Dan Phan

Hi there! 👋
I'm an aspiring data scientist passionate about creating innovative solutions.
During my free time, I love recording and sharing music. 🎶
Connect with me:
- ✉️ Email
- 🌐 LinkedIn
- 🎵 SoundCloud
View the Project on GitHub Trung-Dan-Phan/data-science-portfolio
Data Scientist
About Me
I recently graduated from the joint Master’s in Data Science & AI for Business at École Polytechnique and HEC Paris. I have delivered measurable impact at NielsenIQ (+2% model accuracy) and through strategic recommendations to BCG-X, L’Oréal, and Schneider Electric.
Fluent in English and French, with international experience from my studies at McGill University, I bring a rare combination of technical rigor and business intuition. I am passionate about solving real-world problems with data, and outside of work, I enjoy tennis 🎾, playing the clarinet 🎵, and producing music.
Career Goal: Seeking a Data Scientist or Machine Learning role where I can leverage my technical expertise and business insights to drive impactful solutions.
🧠 Core Competencies
| Programming & Data | ML & AI | Cloud & Big Data | Deployment & MLOps | Visualization |
|---|---|---|---|---|
| Python, SQL, Git | Regression, Classification, Clustering, Time Series Forecasting, NLP, Deep Learning, Recommender Systems | GCP, AWS, PySpark | MLflow, Docker, Prefect, Streamlit, CI/CD | Tableau, Plotly, Matplotlib, Seaborn |
🎓 Education
École Polytechnique / HEC Paris — Master of Science in Data Science & AI for Business (2023–2025)
- GPA: 3.93 / 4
McGill University — Bachelor of Commerce, Major in Mathematics, Concentration in Business Analytics (2019–2022)
- GPA: 3.82 / 4
💼 Professional Experience
NielsenIQ – Multimodal Product Classification (Apr–Aug 2024)
Problem: Manual product categorization across 40+ markets created inconsistent pricing analytics, limiting automation and cross-market comparisons.
Approach: Built scalable data pipelines in BigQuery and AWS S3 to process over 50M records, and designed a multimodal transformer (text + numeric + categorical inputs) using HuggingFace, Databricks, and MLflow. Integrated model monitoring and versioning for continuous improvement.
Impact: Improved classification accuracy by +2% across 20+ categories, enhancing pricing accuracy and enabling large-scale automated analytics across global markets.
 Multimodal transformer architecture integrating text, numeric, and categorical features
Multimodal transformer architecture integrating text, numeric, and categorical features
BCG-X – Customer Churn Prediction & AI Strategy (Feb 2025)
Problem: The client faced increasing customer churn and lacked data-driven segmentation to identify high-risk customers early.
Approach: Developed a logistic regression model with optimized feature engineering to predict churn, achieving 96% precision. Complemented modeling with strategic retention insights and scenario simulations.
Impact: Model insights projected to increase retention by 50% and deliver €150M potential revenue uplift. Adopted as a core component of the client’s CRM retention strategy.
 Overview of model inputs, outputs, and projected business impact
Overview of model inputs, outputs, and projected business impact
L’Oréal – Marketing Mix Modeling (Feb 2025)
Problem: Marketing teams struggled to quantify the impact of ad spend across channels and optimize budget allocation for ROI on Elseve product sales.
Approach: Trained a Marketing Mix Model (MMM) using Google Meridian on $10M+ A&P data, integrating online/offline channel effects and time lags.
Impact: Achieved R² = 0.81 and identified optimal spend reallocations across 20+ channels, enabling €150K+ potential cost savings while maintaining performance.
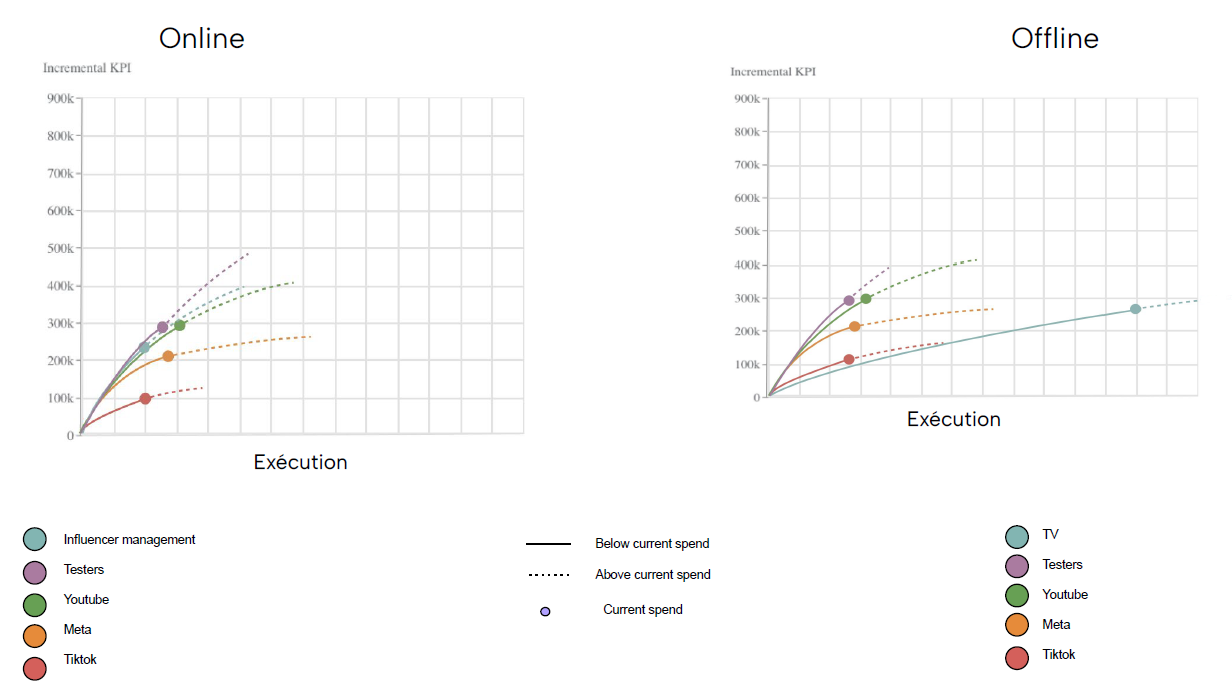 Response curves by marketing channel illustrating online vs offline sales impact
Response curves by marketing channel illustrating online vs offline sales impact
Eleven Strategy – AI-Driven Client Selection for Luxury Events (Jan 2025)
Problem: The client struggled to target high-value customers for luxury events, resulting in low attendance and inefficient campaign spending.
Approach: Developed a client attendance prediction model (92% accuracy) using historical purchase and event data (50K+ records). Built an interactive Streamlit app for marketing teams to dynamically generate invitation lists.
Impact: Improved event attendance efficiency and enabled precise, data-driven targeting of high-value clients, reducing marketing waste.
 Streamlit demo generating client invitations based on event type
Streamlit demo generating client invitations based on event type
Unibail-Rodamco-Westfield – Retail Performance & Mix Optimization (Jan 2025)
Problem: The client lacked a unified view of mall performance across different markets, complicating strategic investment and leasing decisions to maximize foot traffic, sales, and mall revenues.
Approach: Consolidated 6 datasets (15K+ rows) to compute key performance metrics (revenue, traffic, cost efficiency). Applied clustering to group 30+ malls across 10 countries into performance-based segments.
Impact: Delivered actionable segmentation insights that guided regional strategy, improving mall mix optimization and operational efficiency.
 Scatter plot of store share vs performance to identify high-potential branches
Scatter plot of store share vs performance to identify high-potential branches
Schneider Electric – Plastic Cost Prediction (Dec 2024)
Problem: Procurement teams needed to forecast polycarbonate prices for strategic sourcing decisiions, ultimately maximizing profitability and minimizing financial risks associated with plastic materials.
Approach: Implemented a deep learning N-BEATS model using 7 years of cost data. Benchmarked against classical statistical and machine learning models to ensure robustness.
Impact: Achieved lowest MAE (0.115) and was recognized as best-performing team for producing accurate, interpretable forecasts that informed supplier negotiation strategies.
 Comparison of Statistical, ML, and DL models with N-BEATS time series results
Comparison of Statistical, ML, and DL models with N-BEATS time series results
Capgemini Invent – Air Quality Time Series Forecasting (Oct 2024)
Problem: This Kaggle challenge was done as part of an introductory lecture on time series analysis by Capgemini Invent, offering a practical application of forecasting techniques on real-world environmental data.
Approach: Built a hybrid LightGBM + CatBoost ensemble leveraging temporal features, lag variables, and weather data for robust time series forecasting.
Impact: Delivered MAE = 5.74, ranking Top 3 on Kaggle internal leaderboard; model insights supported predictive monitoring initiatives.
 Model performance (MAE) on public and private Kaggle boards for multiple approaches
Model performance (MAE) on public and private Kaggle boards for multiple approaches
Capgemini Invent – Customer Feedback Analysis for TotalEnergies (Jan–Mar 2024)
Problem: TotalEnergies is expecting an intensifying competition to retain customers and wants to listen to customer feedback to better understand and meet customer needs.
Approach: Automated scraping of 200+ review pages (10K+ interactions) with Selenium, applied BERTopic for unsupervised thematic modeling and sentiment analysis.
Impact:
Identified emerging themes and sentiment patterns, enabling data-driven CX strategy recommendations across multiple customer touchpoints.
 BERTOPIC bar chart showing thematic insights from Trustpilot reviews
BERTOPIC bar chart showing thematic insights from Trustpilot reviews
🧩 Projects
Manga Panel Detection & OCR (GitHub Repo)
Problem: While Manga-OCR offers state-of-the-art recognition for complex Japanese text, it lacks tools for direct, real-time use. Japanese learners and translators still face a time-consuming process to extract and understand text from digital manga like Shounen Jump.
Approach: I extended Manga-OCR’s Vision Encoder–Decoder model by building an end-to-end pipeline with YOLOv8 for manga panel detection and OCR integration for web use. The system allows users to capture screenshots, extract text instantly, and fetch dictionary definitions for efficient reading and learning.
Impact: Enabled real-time Japanese OCR from online manga with ~25% higher OCR accuracy compared to generic OCR tools (PaddleOCR), based on Character Error Rate (CER) on Manga109 test samples (~10k). Reduced manual text lookup time by ~50%, creating an accessible tool for language learners and translators.
Manga Recommender System (GitHub Repo)
Problem: Most manga recommendation systems rely on simple popularity metrics and fail to capture user taste similarity effectively.
Approach: Implemented a collaborative filtering system (SVD) on 10K+ titles and users. Automated retraining and evaluation pipelines using Prefect and CI/CD with GitHub Actions, optimizing model performance through hyperparameter tuning.
Impact: Achieved MAE = 0.637 and Precision@10 = 0.981, significantly improving personalized recommendations. The project runs an end-to-end automated ML pipeline with runtime under 15 minutes.